2023年4月25日,StataCorp LLC 正式宣布 Stata 18 上线啦!
或许各位老师、Stata 爱好者们还没把 Stata 17 捂热,StataCorp LLC 就高效地推出了Stata 18。工欲善其事,必先利其器。StataCorp LLC 正如“有匪君子,如切如磋,如琢如磨”,将 Stata 这一利器打造得日益精良与强大。Stata中国授权经销商及合作伙伴友万科技联合山东大学陈强教授团队,第一时间为大家总结了此次发布的十大功能亮点,帮助大家快速了解Stata 18 强大的新功能!
Stata之所以能成为当下流行的计量经济学软件,根本原因在于Stata十分贴近计量经济学的实践应用。此次Stata 18的全新升级,一如既往地切中了时下实证研究的热点与痛点。总结起来,主要有以下十大方面,下面将分别介绍:
1. 异质性DID
2. 中介效应
3. 多向聚类标准误
4. 野聚类自助法
5. 工具变量分位数回归
6. 贝叶斯模型平均
7. 描述性统计制表
8. 数据编辑器的改进
9. Do文件编辑器的改进
10. 全新的画图风格
异质性DID
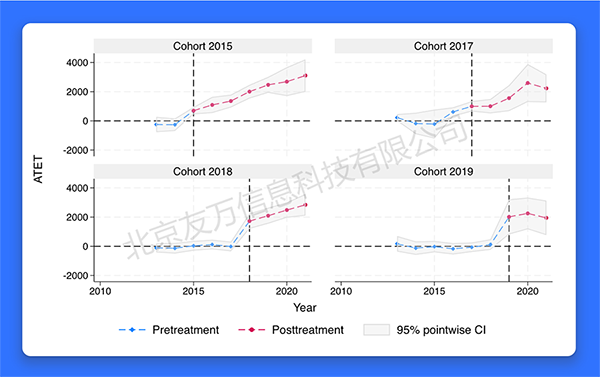
双重差分法(DID)是最常用的计量方法,近年来发展迅速,尤其在“交叠DID”(staggered DID)的领域。对于多期DID模型,若个体受到处理的初始时间不尽相同,且处理状态不可逆(irreversible treatment),则称为“交叠DID”(staggered DID)。传统的双向效应估计量(TWFE)及事件分析法(event study)均依赖于处理效应的同质性假设。然而,对于交叠DID,若处理效应存在异质性(即处理效应随个体或时间而变),则无论TWFE或事件分析法均存在偏差。为此,Stata 18推出了在异质性处理效应的情况下也成立的异质性DID新命令hdidregress与xthdidregress,其中前者适用于重复截面数据,而后者适用于面板数据。
中介效应
中介效应分析是常见的机制分析方法,用于考察因果效应通过何种渠道而产生。例如,若研究发现“锻炼”(exercise)可提升“身心健康”(well-being),我们想进一步知道,此效应是否(部分地)通过改变“荷尔蒙水平”(hormone level)这一中介(mediator)而起作用,参见下图。
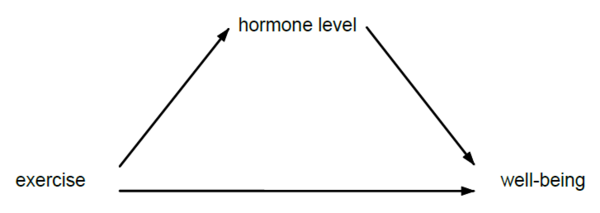
为此,Stata 18推出了新命令mediate,可自动进行中介效应分析,并将总效应(total effect)分解为直接效应(direct effects)与间接效应(indirect effects)。
多向聚类标准误
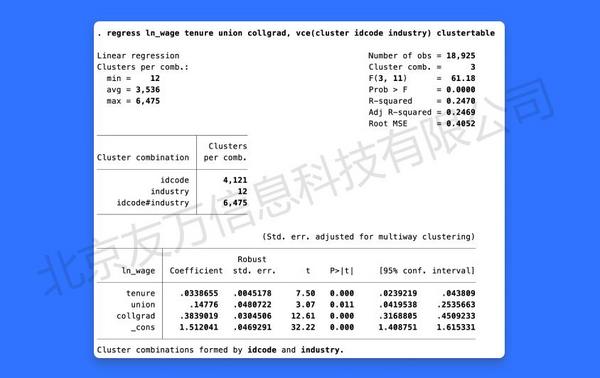
统计推断是实证分析的核心之一,而正确的标准误则是统计推断的核心。针对线性回归模型(例如使用regress, areg或xtreg,fe估计的模型),Stata 18提供了适用于更多场景的稳健标准误。例如,面板模型传统上使用以个体为聚类变量的聚类稳健标准误。然而,面板数据的聚类可能发生在多个维度,包括个体维度(同一个体不同期的扰动项存在自相关)与时间维度(同一时期不同个体的扰动项存在自相关)。Stata 18提供了估计“多向聚类标准误”(multi-way cluster standard errors)的方便选项。例如,使用选择项“vce(cluster clustvar1 clustvar2)”即可估计“双向聚类标准误”(two-way cluster standard errors),而选择项“vce(cluster clustvar1 clustvar2 clustvar3)”则可提供在三个维度聚类的聚类标准误,以此类推。
野聚类自助法
在使用聚类稳健标准时,通常要求聚类数目较大,才能保证所估标准误为真实标准误的较好近似。然而,现实数据的聚类数目可能较小,而每个聚类内部的观测值也不均衡。此时,使用渐近理论计算的聚类标准误可能存在较大偏差,而“野聚类自助法”(wild cluster bootstrap)则可提供计算标准误的更优方法。所谓“野自助法”就是一种“残差自助法”(residual bootstrap),即对残差进行自助抽样;而“聚类自助法”则意味着以聚类为单位进行自助抽样。为此,Stata 18推出了新命令wildbootstrap,可方便地估计线性模型的野聚类标准误,例如
. wildbootstrap regress y x1 x2
. wildbootstrap areg y x1 x2, absorb(x3)
. xtset id
. wildbootstrap regress y x1 x2
工具变量分位数回归
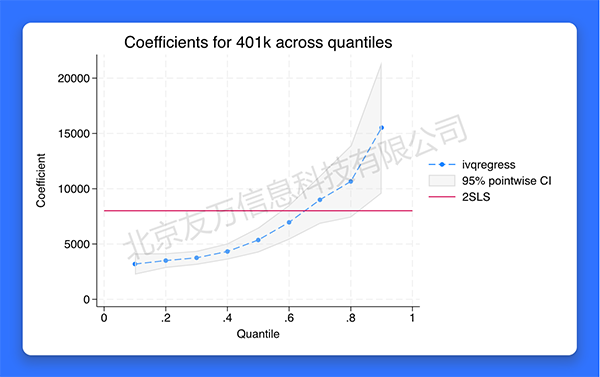
常见的均值回归仅考察解释变量如何影响被解释变量的均值;而分位数回归则可度量对被解释变量各分位数的影响,从而全面刻画对被解释变量条件分布的作用。但原有的Stata分位数回归命令qreg假定所有解释变量均为外生。然而,内生变量在实证研究中很常见。为此,Stata 18推出了新命令ivqregress,可对分位数回归模型进行工具变量法的估计,并进行内生性检验(endogeneity test),以及提供在弱工具变量下也成立的稳健置信区间(confidence intervals that are robust to weak instruments)。
贝叶斯模型平均
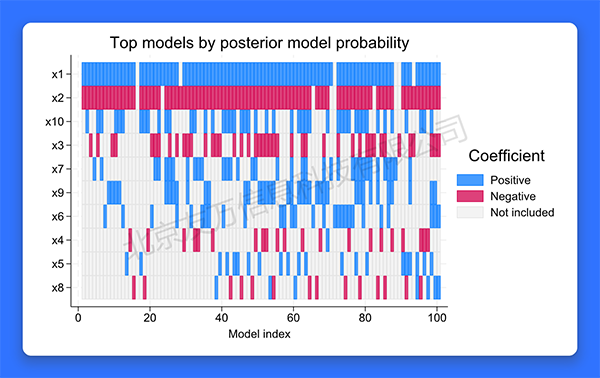
实证研究的一个基本问题是模型选择(model selection)。传统做法是通过信息准则等方法,选择最优模型。但我们依然可能选错模型,从而导致偏差。面对模型的不确定性(model uncertainty),更稳健的做法可能是,同时估计多个模型,并通过贝叶斯原理评估每个模型的发生的概率。然后,以此概率为权重,对所有模型进行加权平均,即所谓“贝叶斯模型平均”(Bayesian model averaging,简记BMA)。为此,Stata 18推出了新命令bmaregress,可对线性回归模型自动进行BMA估计与预测。
描述性统计制表
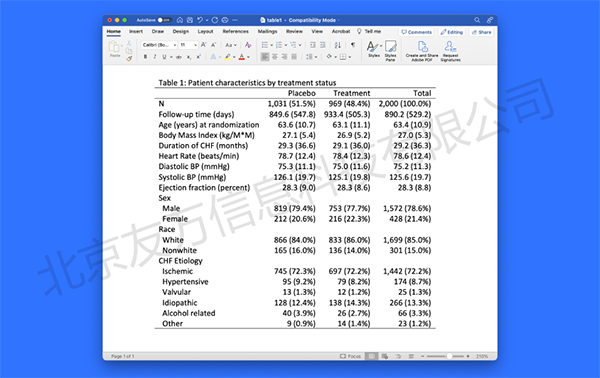
实证论文的“Table 1”通常都是描述性统计(descriptive statistics)。Stata 18新推出了dtable命令,可方便地将连续变量与离散变量的统计特征制表。用户可选择汇报何种统计量,或根据离散变量的取值将数据分为若干子样本,并比较相应的统计量。用户还可定制表格的具体形式,并将其输出到Word,Excel, HTML, Markdown, PDF, LaTex, SMCL或文本文件。
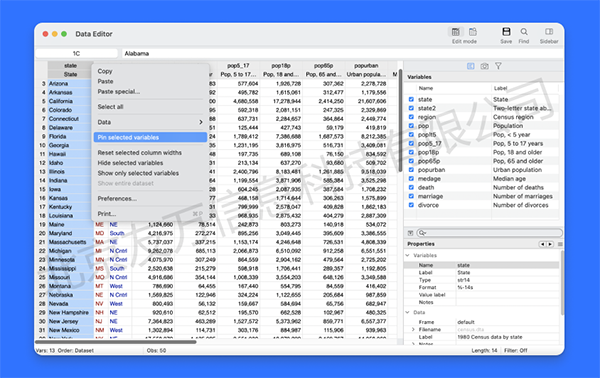
数据编辑器的改进
Stata 18 对数据编辑器作了诸多方便用户的改进,这包括
●可固定的行与列 (pinnable rows and columns)。在使用数据编辑器翻看数据时,已固定的行或列(pinned rows or columns)并不会随之滚动。这使得察看与比较数据更为方便;例如,可固定表示ID的变量。
●调整字符串的显示格子 (resizable cell editor for string data)。在编辑字符串数据时,可通过调整显示格子,以展示更多字符串,而不至于被隐藏。
●截断文本的提示框 (tooltips for truncated text)。在显示格子中,若文本因太长而被截断,只要将鼠标放于格子上,即会弹出包含完整文本的提示框。
●支持比例宽度字体 (proportional-width font support)。这将有助于提高数据的可读性,并允许同时展示更多变量,而无须滚动。
●在列标题显示变量标签 (show variable labels in column header)。变量标签将直接在变量名之下展示,这将有助于察看变量名不够直观的数据。
●通过新的键盘快捷键隐藏或显示变量的取值标签 (new keyboard shortcut for hiding or showing value labels)。这将便于用户在显示数值(numeric values)与标签(labels)之间快捷地切换。
Do文件编辑器的改进
Stata 18对于Do文件编辑器做了进一步的改进,包括
●自动备份 (automatic backup)。以Do文件编辑器打开的所有文件都将周期性地自动存盘备份,以防止因意外关机而丢失程序。
●用户指定关键词的语法高亮 (syntax-highlight for user-defined keywords)。用户可以自行指定对哪些关键词进行语法高亮显示,并选择高亮的颜色与字体(粗体或斜体)。
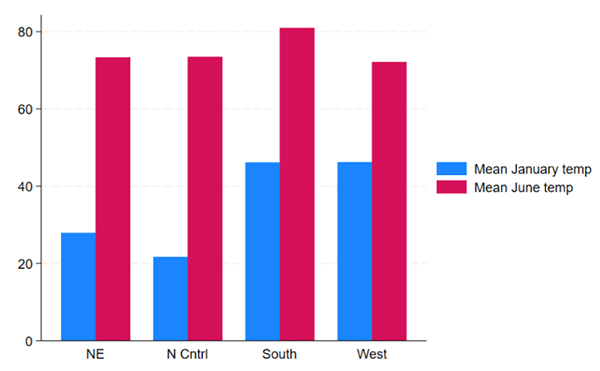
全新的画图风格
Stata 18带来了全新的画图风格。新的默认画图风格将包括许多用户渴望的如下特征:
●白色背景 (white background)
●带有亮色的更新调色板 (updated color palette with bright colors)
●y轴标签的水平展示 (horizontal y-axis labels)
●更宽的宽高比 (wider aspect ratio)
●某些图可实现图例的动态放置 (dynamic legend placement for certain graphs)
●其它更多特征
例如,这是在新风格下的条形图:
对比旧风格下的条形图:
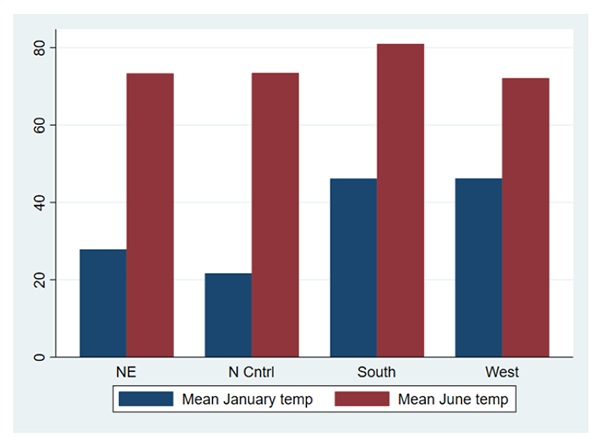
事实上,Stata 18 引入了四个新的画图风格,即 stcolor, stcolor_alt, stgcolor与stgcolor_alt。其中,stcolor 为默认风格,而其余风格为提供了对于图片宽度与图例放置的不同选择。
(版权申明:本文章为原创,转载请说明出处)