Python作为一门面向多对象的编程语言,简洁的语法使得编写数十行代码即可实现各种数据分析功能。在研究海量数据时使用Python更加简单且效率高的处理分析数据。随着数据时代的到来,越来越多的学校开设Python课程,除了学生,老师也开始更加精益的要求提高自己的教学水平和科研水平。
2023年1月31日-2月2日,由北京友万信息科技有限公司主办,佛山科学技术学院承办的,为期三天的“Python数据分析定制内训课程”就是为此而来。本次课程受环境因素影响依旧采用线上直播的方式进行。虽然还在寒假期间,佛山科学技术学院老师们的学习热情依旧高涨,除了相关课程的授课老师进行进修,还有许多其他老师一同学习。此次培训为佛山科学技术学院内部定制的高级培训课程,共有三十余人参加,专属定制课程内容和效果受到了参培人员的一致好评。
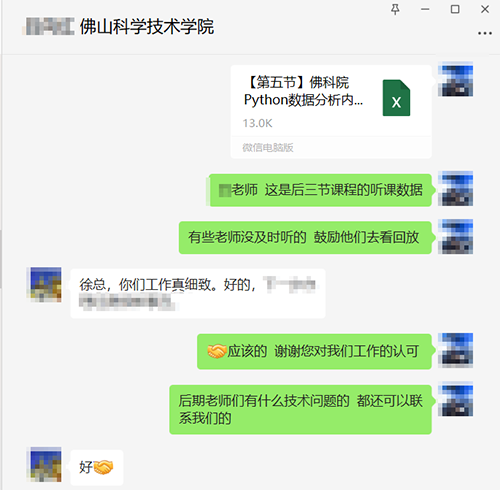
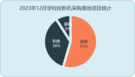
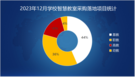
参培学员好评反馈
本次课程由北京友万信息科技有限公司签约讲师:袁铭老师主讲,全面介绍了使用Python进行数据分析所必需的各项知识。
包括数据分析的基本流程、Python数据分析环境搭建与Python编程基础、数据分析与统计分析、回归分析、分类与聚类算法、时间序列分析以及机器学习前沿专题等。
本课程所有教学模块均有实战项目以及高度可复用的源代码配套,并且能够与相关课程做到有机结合。通过本课程学习,学员能够掌握数据分析、数据挖掘的基本过程以及相关核心技术,初步具有数据科学的思维方式,能够从数据分析的角度对社会经济现象进行研究与解释。
本课程的三大特色:
第一,贴近实战的教学模块安排。
本课程将从主讲人实际参与企业级数据挖掘的经验出发,从讲解 Python 环境搭建、Python 编程基础开始,逐渐过渡到结合实际案例的数据探索与分析。在具有一定积累后,将全面介绍回归、分类、聚类、推荐系统等统计建模与数据挖掘工具。课程最后将对一些数据科学领域的前沿例如集成学习、深度学习等进行介绍。
第二,平缓的学习曲线。
课程整体以及课程的每一个教学模块均遵循从易到难的教学规律,并设置大量“所见即所得”的课堂练习,使参与者能够从学习过程中产生获得感。特别地,主讲人将从自身教学经验出发,化解学员学习过程中的难点与“痛点”,保持学习热情。
第三,高度可复用的代码模块。
本课程提供的教学代码均具有高度可复用性,经过适度修改可以用于绝大部分数据分析与数据挖掘的实际工作与教学活动。
第一天袁老师先分享了数据分析概念,介绍了数据思维,现在社会的数据分析所需要的主流软件。接下来开始带大家了解Python。先介绍了Python的6个基本模块:Python编程环境搭建、功能模块安装、Python控制语句、Python内置数据结构、Python的函数与类、Numpy简介。让听课学员能够在最开始就明确Python的基本组成,为后续课程打下基础。

模块内容简介
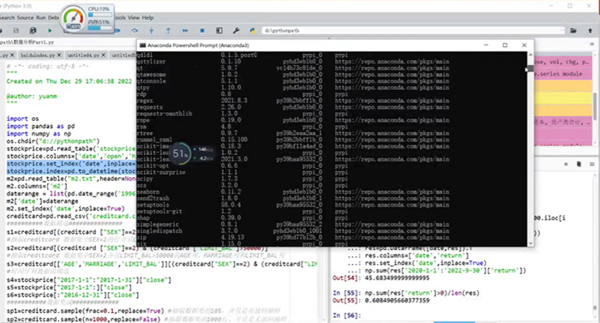
介绍完Python的基础知识后,接下来讲解第三部分:基本的数据分析,主要分为Pandas简介;数据导入;数据筛选与数据集成;缺失值处理。
讲解这部分的时候,袁老师讲述了一些他的个人使用窍门。同时表示涉及的代码,最好是自己手动敲一遍,增加代码熟悉度。

基本的数据分析
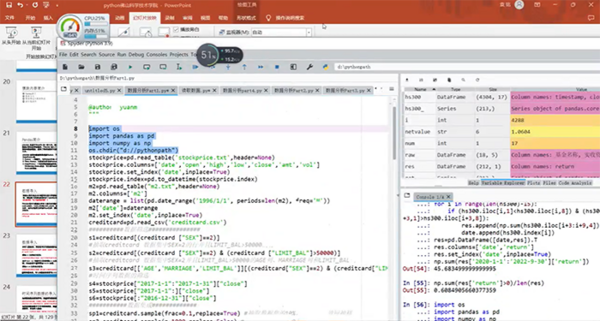
第四部分讲解了基本的统计分析。这部分内容可以和统计学原理,完美结合。包括数据的频数分析;集中趋势分析;离散程度分析;分布以及一些基本的统计图形。

基本的统计分析
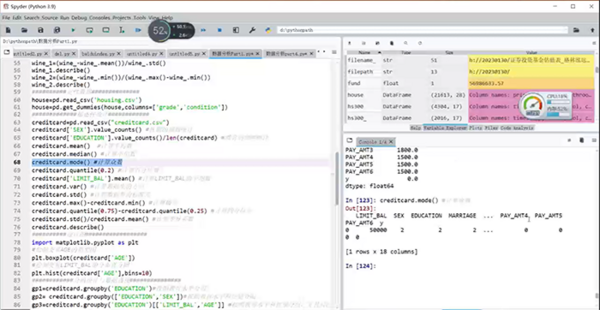
第五部分讲解了基本的时间序列分析。包含频率转换;环比、同比与定基;环比、同比与定基增长率;时间序列的预测;Holt-winters方法;ARIMA模型;其他的时间序列预测包。

基本的时间序列分析
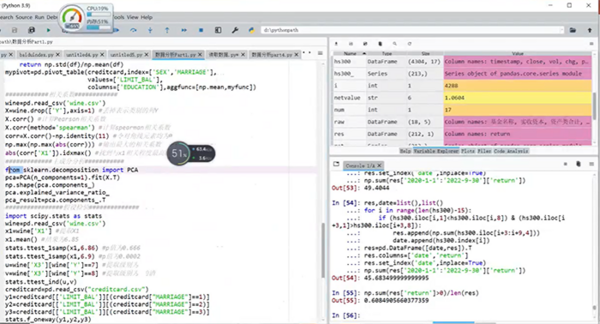
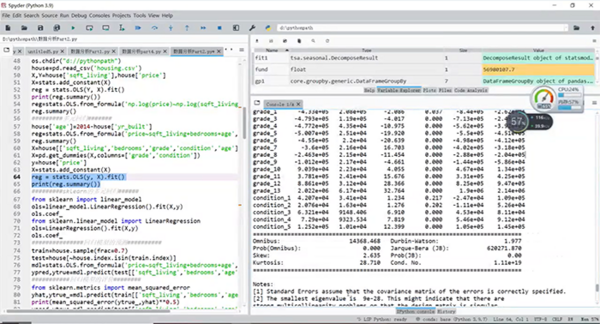
第六部分讲解了回归分析。包括Statsmodel包中的回归分析;多元线性回归模型;Sklearn中的回归分析;回归模型的预测;回归模型的评价。
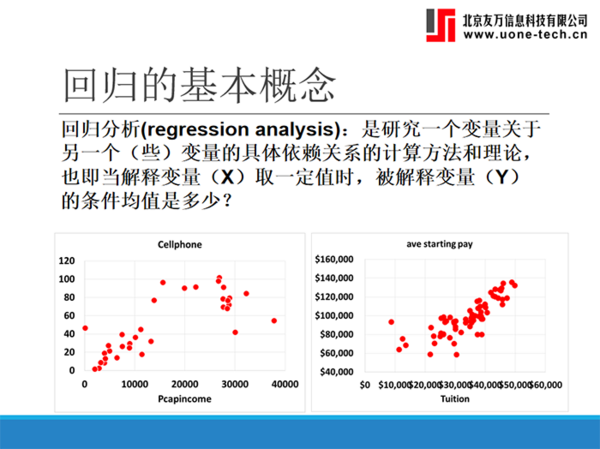
回归分析
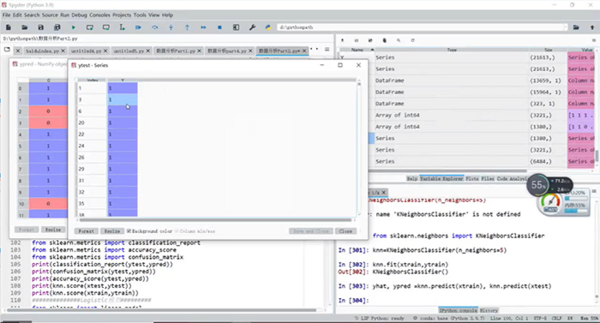
第七部分讲解了统计分类。典型的分类算法有:logistic回归、决策树、朴素贝叶斯、kNN等。
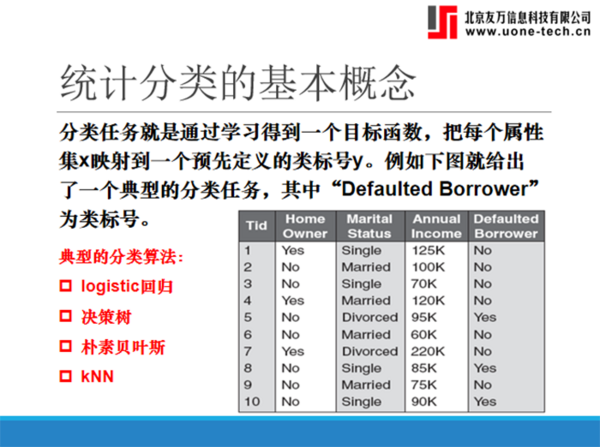
统计分类
第八部分讲解了聚类算法与推荐算法。包括:聚类分析;聚类算法;Kmeans算法;推荐算法等等。

聚类算法

推荐算法
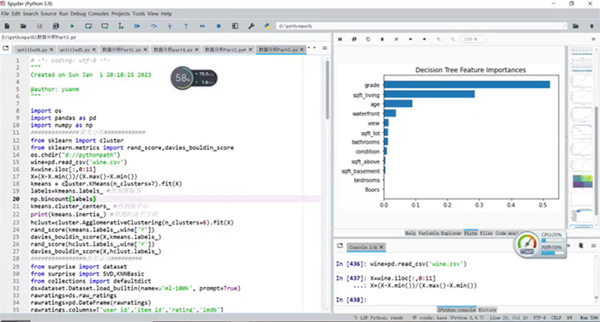
第九部分讲解了集成学习。包含集成学习的含义;集成学习的分类;学习器的方差、偏差和误差;随机森林、AdaBoost、GBDT等内容。

集成学习
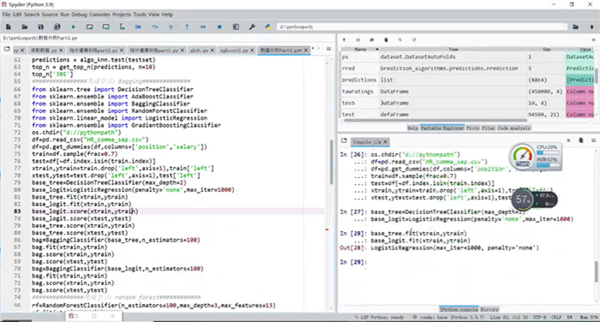
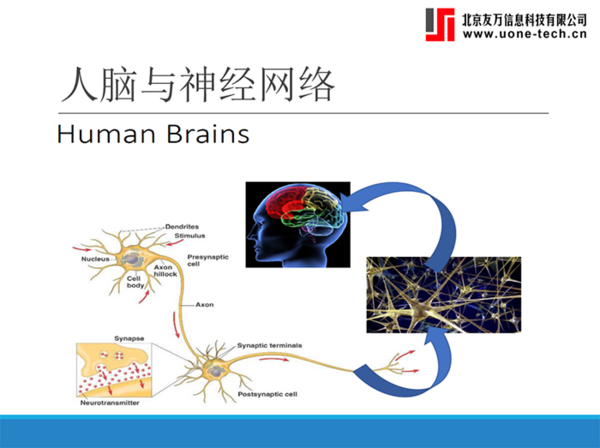
第十部分讲解的是神经网络模型。包括人脑与神经网络;感知器;人工神经网络;激活函数;神经网络模型的训练;人工神经网络的实现。
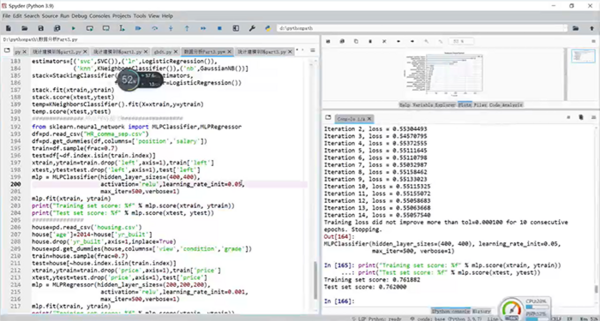
第十一部分增添了文本挖掘的知识拓展:文本挖掘、文本分类等知识。

三天的课程大纲如下:
| 第一天 | 第二天 | 第三天 |
模块 1:数据分析概述 1.1 数据思维 1.2 数据分析流程 1.3 数据分析软件平台简介 1.4 Python 语言简介 模块 2:Python 编程基础 2.1 Python 编程环境搭建 2.2 功能模型介绍与安装 2.3 Python 控制语句 2.4 Python 内置数据结构 2.5 Python 的函数与类 2.6 Numpy 简介 模块 3:基本的数据分析 3.1 Pandas 概述 3.2 数据导入 3.3 数据筛选与数据集成 3.4 数据清洗 | 模块 4:统计分析 4.1 基本的描述性统计分析 4.2 分组统计与数据透视 4.3 多元统计分析 4.4 数据可视化基础 4.5 假设检验 模块 5:回归分析 5.1 回归与回归模型 5.2 回归模型的评价与预测 5.3 多元回归模型 5.4 如何处理定性数据 模块 6:统计分类 6.1 分类算法概述 6.2 KNN 算法 6.3 Logistics 模型 6.4 决策树模型 6.5 分类模型评价 | 模块 7:聚类算法与推荐算法 7.1 聚类算法概述 7.2 Kmeans 算法 7.3 聚类模型性能评价 7.4 推荐算法 模块 8:时间序列分析 8.1 时间序列数据的基本处理 8.2 环比、同比、定基增长率 8.3 时间序列分解 8.4 时间序列预测 模块 9:前沿专题与教学经验分享 9.1 集成学习 9.2 神经网络模型 9.3 教学经验分享 模块10:文本挖掘 |
北京友万信息科技有限公司作为中国大陆领先的教育和科学软件分销商,已在中国300多所高校建立了可靠的分销渠道,拥有最成功的教学资源和数据管理专家。友万科技将在未来努力帮助国内高校建立科学领先的教育体系,熟练运用基本功学习高效的科研方法,并能够有效地推广科学软件,同时向中国用户提供高质量的客户支持和培训服务。合作热线: 010-56548231












![聚酰胺粉 [柱层析用,高分离性能] 60-100目/80-120目/100-200目](https://p-06.caigou.com.cn/135x120/2024/7/2024071513085253637.jpg)