文 / Chuck Huber, Director of Statistical Outreach at StataCorp
导读
在之前的文章中,作者演示了如何利用蒙特卡罗模拟计算功率的t检验的示例,以及如何把你的模拟集成到Stata的power命令中。本文,作者将向您展示如何为线性和逻辑回归模型执行这些任务。线性回归和逻辑回归程序的策略和整体结构类似于t检验示例。不同点在于数据模拟和用于检验零假设的模型。
在模拟回归模型时,选择现实的回归参数是很具有挑战性的。有时,pilot data 或historical data可以提供思路,但通常我们会考虑一系列我们认为有意义的参数值。本文将通过基于全国健康和营养检查调查 (NHANES) 数据做为示例。可以通过键入webuse nhanes2来下载这些数据的一个版本。
线性回归示例
假设您正在计划一项systolic blood pressure (SBP) 研究,并且您认为年龄和性别之间存在相互作用。NHANES 数据集包括变量bpsystol (SBP)、age和sex。下面,我们拟合了一个线性回归模型,其中包括一个age与sex的交互项,并且所有参数估计的p值都等于 0.000。这并不奇怪,因为该数据集包含 10,351个观测值。当其他一切保持不变时,随着样本量变大,p值变小。
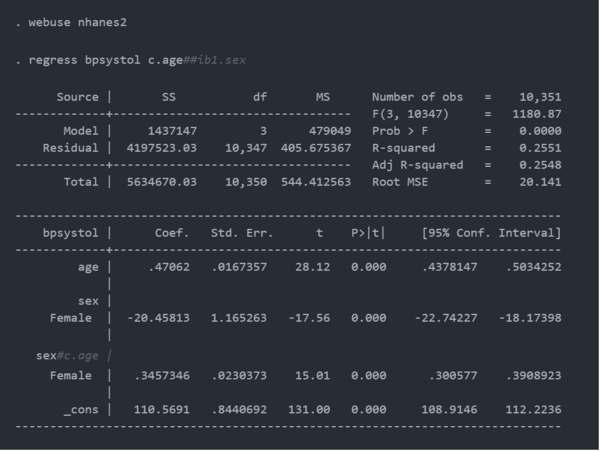
也许您没有资源为您的研究收集 10,351名参与者的样本,但如果希望有 80%的功效来检测0.35的交互参数。您的样本需要多大?
让我们首先根据 NHANES 模型的参数估计创建单个伪随机数据集。我们通过清除Stata的内存开始下面的代码块。接下来,我们将随机种子设置为 15,以便我们可以重现我们的结果并将观察次数设置为 100。
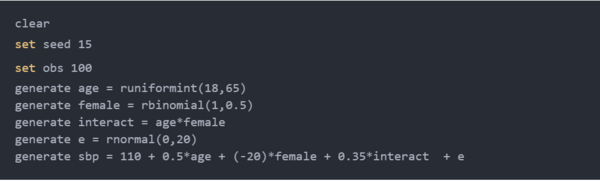
代码块的第四行生成一个名为age的变量 ,其中包括从区间[18,65]上的均匀分布中提取的整数。
第五行使用概率等于0.5的 Bernoulli distribution 生成一个名为female的指示变量。回想一下,一次试验的二项式分布等价于 Bernoulli distribution 。
第六行生成了 age和 female交互作用的变量。
第七行生成一个变量e,即回归模型的误差项。生成了误差由均值为 0且标准差为 20的正态分布。值 20基于从NHANES回归模型估计的root MSE。
代码块的末行基于我们的模拟变量和来自NHANES回归模型的参数估计的线性组合生成变量sbp。
以下是使用regress拟合我们的模拟数据的线性模型的结果。参数估计与我们的输入参数有些不同,因为我只生成了一个相对较小的数据集。我们可以通过增加样本大小、抽取大量样本或两者兼而有之的方式来减少这种差异。
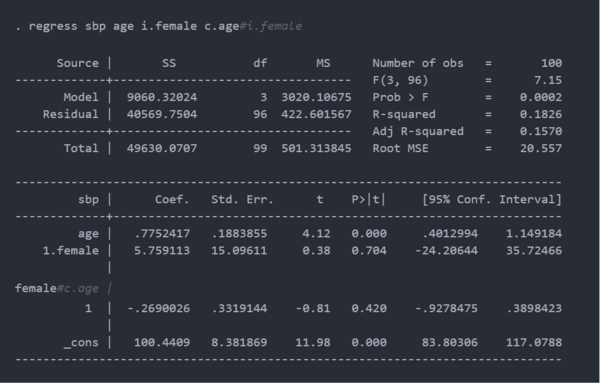
交互作用项的p值等于 0.420,这在 0.05水平上不具有统计显着性。显然,我们需要更大的样本量。
我们可以使用回归模型中的p值来检验交互项为零的原假设。这在本例中是可行的,因为我们只测试一个参数。但是,如果我们的交互包含一个分类变量,例如race,我们将不得不同时测试多个参数。有时我们希望同时测试多个变量。
Likelihood-ratio tests可以检验多种假设,包括同时检验多个参数。我将在本示例中向您展示如何使用Likelihood-ratio tests,因为它将涉及到您在研究中可能遇到的其他假设。如果您不熟悉它们,您可以在Stata Base Reference Manual中阅读有关likelihood-ratio tests的更多信息。
下面的代码块显示了用于计算likelihood-ratio tests的五个步骤中的四个。我们将检验交互项的系数为零的原假设。首行拟合包含交互项的“full” 回归模型。第二行将完整模型的估计值存储在内存中。“full”这个名字是任意的。我们可以给这个模型的结果命名任何我们喜欢的名字。第三行拟合了省略交互项的 “reduced” 回归模型。第四行将简化模型的结果存储在内存中。

第五步使用lrtest计算完整模型与简化模型的 likelihood-ratio test。该检验产生0.4089的p值,接近上述回归输出中报告的 Wald 检验。我们不能拒绝交互参数为零的原假设。

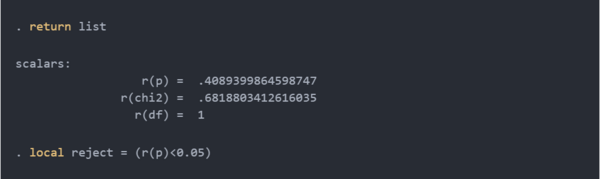
您可以键入return list以查看存储在标量r(p)中的p值。您可以使用r(p)来定义reject,就像我们在t测试程序中所做的那样。
模拟数据和检验回归模型的零假设比t检验稍微复杂一些。但是编写一个程序来自动化这个过程几乎与t测试示例相同。让我们考虑下面的代码块,它定义了程序simregress。
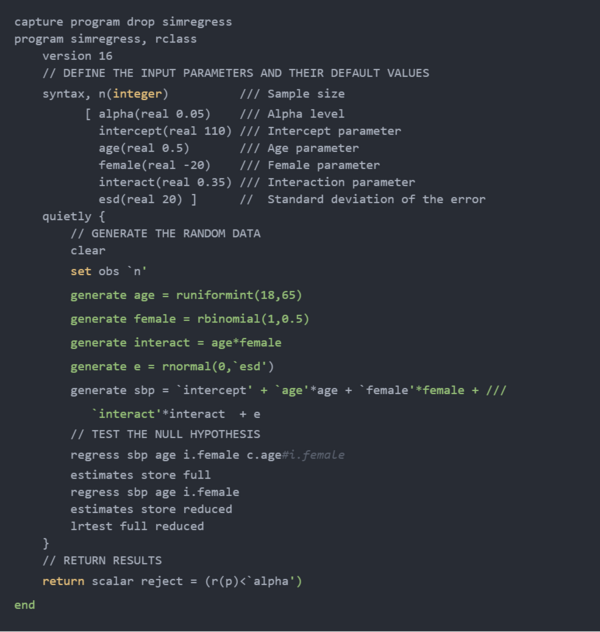
前三行以capture program、program和version开头,与我们的t测试程序基本相同。
该程序的语法部分与t测试程序的语法部分类似,但输入参数的名称显然不同。已经包含了样本大小、alpha 级别和基本回归参数的输入参数。我们没有为模型中的每个可能的参数都包含一个输入参数,但如果你愿意,也可以这样做。例如,在我们的程序中将变量age的范围“hard coded”为18到 65。但是,如果您愿意,也可以包含age上限和下限的输入参数。我还发现包含描述参数名称的注释很有帮助,这样就不会产生歧义。
下一段代码嵌入在一个 “quietly”的块中。像set obs、generate和regress这样的命令将输出发送到结果窗口和日志文件(如果你打开了)。将这些命令放在一个quietly块中会抑制该输出。
我们已经编写了创建随机数据和检验零假设的命令。因此,我们可以将该代码复制到quietly块中,并用语法定义的相应本地宏替换任何输入参数。例如,我已将set obs 100更改为set obs 'n',以便观察的数量将由语法指定的输入参数设置。我还为输入参数指定了与模型中模拟变量相同的名称。所以'age'*age是syntax定义的输入参数'age'和模拟生成的变量age的乘积。
likelihood-ratio test的p值存储在标量r(p)中,我们的程序返回标量reject ,与在我们的t测试程序中完全一样。
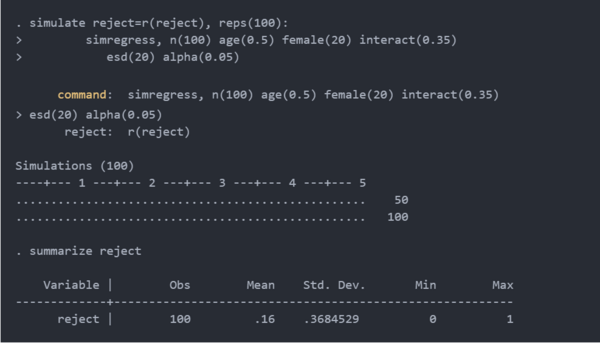
下面,我使用simulate运行simregress 100次并summarized变量reject。结果表明,给定 100名参与者的样本和关于模型的其他假设,我们将有16%的功效来检测 0.35的交互参数。
接下来,我们编写一个名为power_cmd_simregress的程序,以便我们可以将simregress集成到 Stata 的power命令中。power_cmd_simregress的结构与上一篇文章中的power_cmd_ttest相同。首先,我们定义语法和输入参数并指定它们的默认值。然后,我们运行模拟并总结变量reject。之后,我们返回结果。
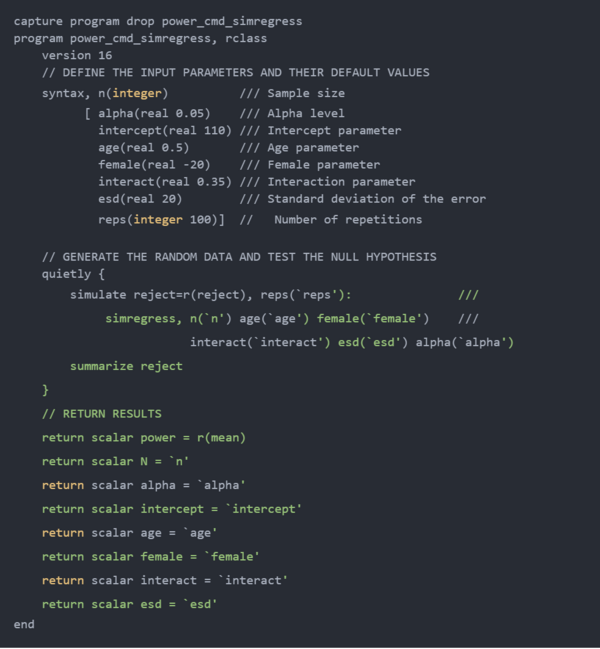
我们还编写一个名为power_cmd_simregress_init的程序。回想一下上一篇文章,该程序将允许我们为一系列输入参数值运行power simregress,包括双引号中列出的参数。
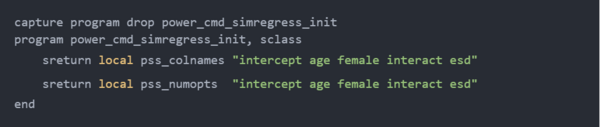
现在,我们已经准备好使用power simregress了!下面的输出显示了当interaction参数等于 0.2到0.4时的模拟功效,增量为0.05,对于大小为 400、500、600和700的样本。
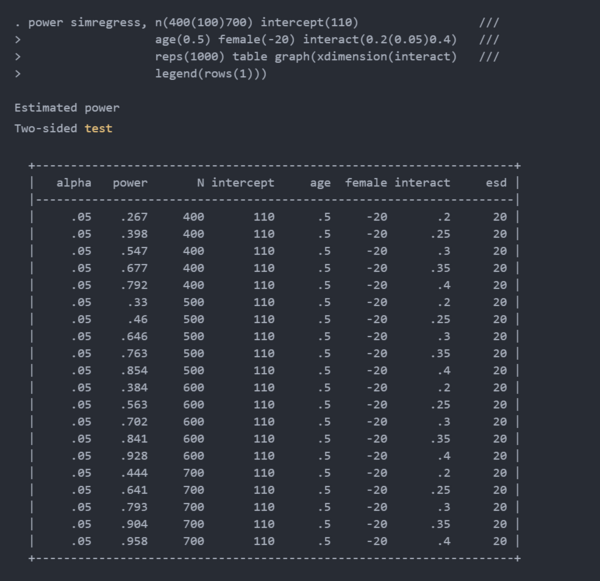
图 1 以图形方式显示了结果。
图 1:回归模型中交互项的估计功效
表格和图表向我们展示了可以产生 80%功效的几种参数组合。700名参与者的样本将使我们有大约 80%的功效来检测0.30的interaction参数。600名参与者的样本将使我们有大约80%的能力来检测 0.33的interaction参数。500名参与者的样本将使我们有大约80%的功效来检测大约 0.37的interaction参数。400名参与者的样本将使我们有大约 80%的能力来检测 0.40的interaction参数。我们对样本大小的选择基于我们想要检测的interaction参数的大小。
此示例侧重于具有两个协变量的回归模型中的交互项。但是你可以修改这个例子来模拟你能想象到的几乎任何类型的回归模型的能力。在规划模拟时,我建议执行以下步骤:
写下感兴趣的回归模型,包括所有参数。
指定协变量的详细信息,例如age 范围或females比例。
找到或考虑模型中参数的合理值。
假设替代假设,模拟单个数据集,并拟合模型。
编写一个程序来创建数据集、拟合模型并使用simulate 来测试程序。
编写一个程序命名为power_cmd_mymethod,它允许运行您的power模拟。
编写一个名为power_cmd_ mymethod_init的程序,以便您可以将 numlists 用于所有参数。
让我们尝试使用这种方法进行逻辑回归模型。
逻辑回归示例
在此示例中,让我们假设您正计划对hypertension ( highbp )进行研究。hypertension是二元的,因此我们将使用逻辑回归来拟合模型并使用优势比作为效应大小。
第 1 步:写下模型
模拟功率的首步是写下模型。logit(highbp)=β0+β1(age)+β2(sex)+β3(age×sex)
我们需要创建变量highbp、age、sex和交互项age×sex。我们还需要指定合理的参数值β0,β1, β2, 和 β3.
步骤 2:指定协变量的详细信息
接下来,我们需要考虑模型中的协变量。什么样的年龄值对我们的研究是合理的?我们对老年人感兴趣吗?年轻的成年人?假设我们对 18到 65岁之间的成年人感兴趣。年龄分布在区间 [18,65]内是否可能是均匀的,或者我们是否期望在年龄中间出现驼峰状分布范围?我们还需要考虑研究中男性和女性的比例。我们是否可能对 50%的男性和 50%的女性进行抽样?这些是我们在规划功率计算时需要问自己的问题。
假设我们对 18到65岁之间的成年人感兴趣,并且我们相信年龄是均匀分布的。我们还假设样本将是 50%的女性。一旦我们为age和sex创建变量,就很容易计算交互项age×sex。
步骤 3:为参数指定合理的值
接下来,我们需要考虑模型中参数的合理值。我们可以根据文献综述、试点研究结果或公开数据来选择参数值。
我选择再次使用 NHANES 数据,因为它包括变量hypertension ( highbp )、age和sex。
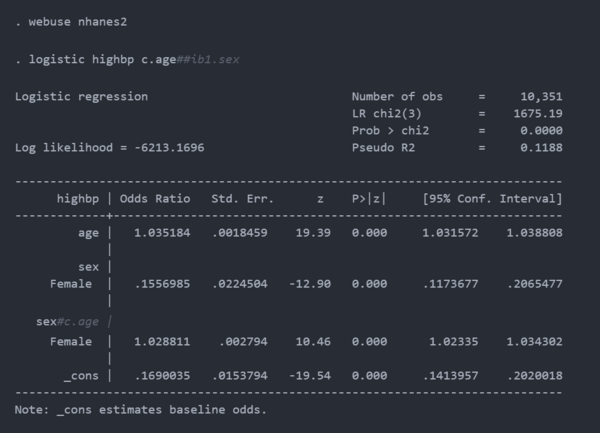
输出模型中每个变量的优势比估计值。优势比是指数参数估计(that is,
),所以我们可以指定优势比的自然对数
作为我们功率模拟中的参数。例如,上面输出中年龄的优势比的估计值为 1.04,因此我们可以指定
我们也可以指定
和
第 4 步:Simulate a dataset assuming the alternative hypothesis, and fit the model
接下来,我们根据我们对替代假设下的模型的假设创建一个模拟数据集。下面的代码块与我们用来为线性回归模型创建数据的代码几乎相同,但有两个重要的区别。首先,我们使用generate xb创建参数和模拟变量的线性组合。参数表示为使用NHANES数据估计的优势比的自然对数。其次,我们使用rlogistic(m,s)从变量xb创建二进制因变量highbp。
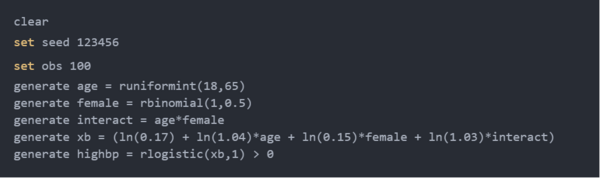
然后,我们可以将逻辑回归模型拟合到我们的模拟数据中。
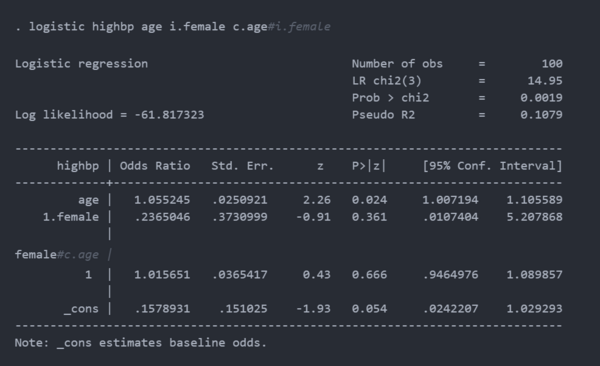
第 5 步:编写程序以创建数据集、拟合模型并使用模拟测试程序
接下来,让我们编写一个程序,在 alternative hypothesis下创建数据集,拟合逻辑回归模型,检验零假设,并使用simulate运行程序的多次迭代。
下面的代码块包含名为simlogit的程序的语法。语法命令中的默认参数值是我们使用 NHANES数据估计的优势比。我们使用lrtest来检验零假设,即age×sex的优势比等于 1。
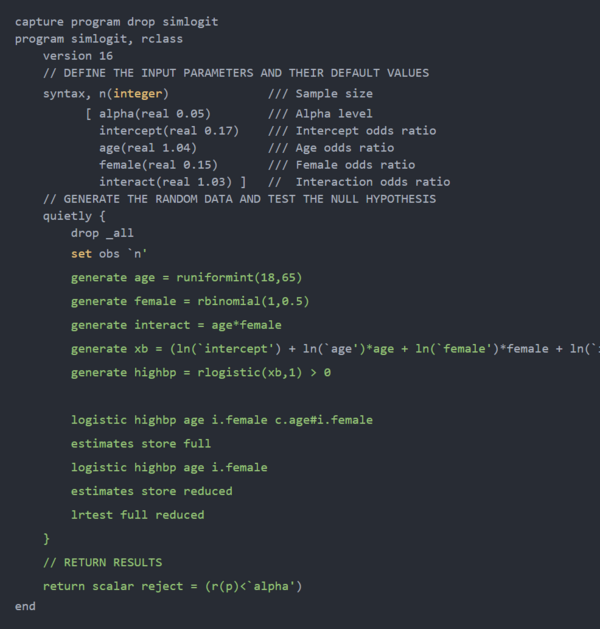
然后,我们使用simulate默认参数值运行simlogit100 次。
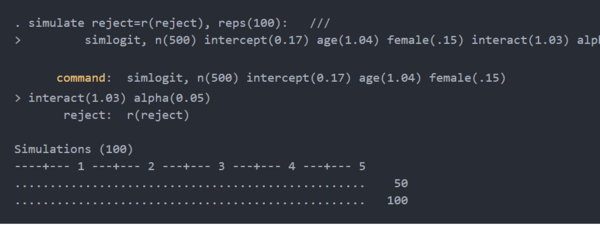
simulate将假设检验的结果保存到名为reject的变量中。reject的平均值是假设样本量为 500 人时,我们估计检测age×sex交互项的优势比为 1.03的能力。

第 6 步:编写一个名为power_cmd_simlogit的程序
如果我们只对一组特定的假设感兴趣,我们可以停止我们的快速模拟。但是编写一个名为power_cmd_simlogit的附加程序很容易,它允许我们使用 Stata 的power命令为一系列样本大小创建表格和图形。

第 7 步:编写一个名为 power_cmd_simlogit_init的程序
编写一个名为power_cmd_simlogit_init的程序也很容易,它允许我们为模型中参数的一系列值模拟功率。
使用power simlogit
现在,我们可以使用power simlogit来模拟各种假设的功率。下面的示例模拟了一系列样本大小和效果大小的功效。样本大小从400到 1000人不等,以 200为增量。以及age×sex交互项的优势比范围从 1.02到 1.05,增量为 0.01。
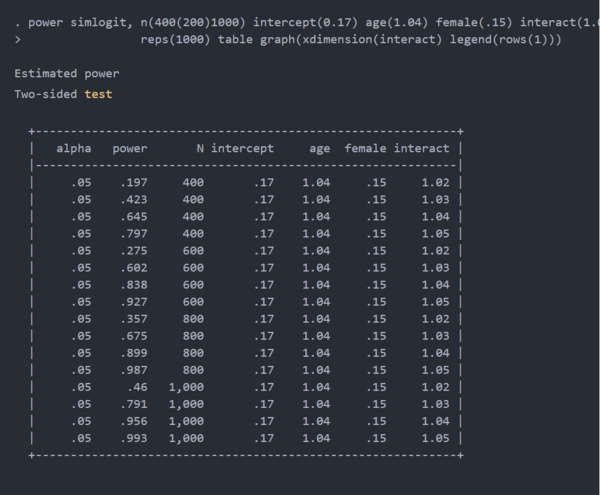
图 2:逻辑回归模型中交互项的估计功效
上面的表格和图表表明,使用样本大小和效应大小的四种组合可实现 80%的功效。鉴于我们的假设, 我们将至少有 80%的功效来检测 600、800和 1000的样本量的优势比为 1.04。我们将有80%的功效来检测1.05的优势比,样本量为 400人。
在这篇文章中,我们展示了如何在线性和逻辑回归模型中模拟交互项的统计功效。您可以根据自己的目的修改上面的示例。
Stata软件订购:
如需订购Stata V17全新版软件,请联系Stata中国授权经销商及合作伙伴北京友万信息科技有限公司(www.uone-tech.cn)。我司拥有强大的售后服务团队,聚合国内一线Stata行业专家为客户提供优质的技术支持服务,并帮助中国用户建立完善的软件服务体系。手机/微信:18610597626 邮箱:crystal@uone-tech.cn。
专注分享商业数据分析、金融数据分析、应用统计分析、知识图谱、机器学习、计量经济、人工智能、网络爬虫、自动化报告与可重复研究等热门技术内容。定向培养Stata、Python、R语言数据人才,助力产学研政企商协同发展,为中国大数据产业蓄能。合作热线:010-56548231 邮箱:info@uone-tech.cn。