文 / Chuck Huber, Director of Statistical Outreach at StataCorp
导读
——————————————————————————————————————————————————————
在作者以前的文章中,使用read_stata()方法将Stata数据集读入pandas 数据框中。当您想将整个Stata数据集读入Python时,这很好用。但是有时我们希望从Stata数据集中读取变量或观察值的子集,或同时读取两者。在本文中,作者将向您介绍Stata Function Interface(SFI)模块,并向您展示如何使用它来将部分数据集读入pandas数据框中。
如果您不熟悉Python,那么在继续阅读之前,请阅读作者的Stata / Python集成系列文章的前四篇文章可能会有所帮助。
设置Stata以使用Python
在Stata中使用Python的三种方法
如何安装Python套件
如何使用Python套件
使用SFI模块将数据从Stata移至Python
该SFI 是一个Python模块,使您可以传递信息来回塔塔和Python之间。您可以复制整个或部分数据集,数据框,局部和全局宏,标量和矩阵,甚至全局Mata矩阵。一篇博客文章中没有太多功能可以显示给您。因此,今天我将向您展示您可能会使用的功能:将部分Stata数据集读取到Python中。我们将在以后的文章中探索更多的SFI功能。
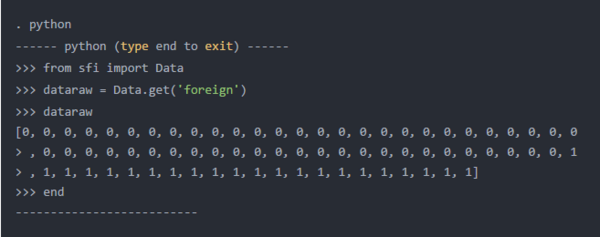
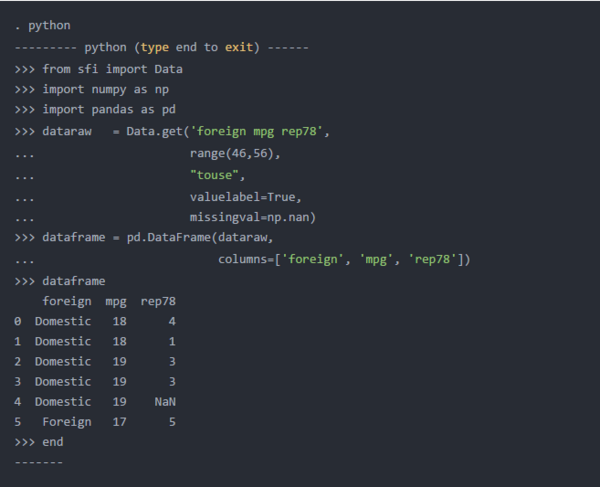
让我们通过使用自动数据集开始下面的代码块。接下来,让我们进入Python环境并从SFI模块导入Data类。然后,我们将使用Data类中的get()方法将外部变量复制到名为dataraw的Python列表对象中。get()方法的第1个参数是放在单引号中的Stata变量列表。

Python输出向我们显示,列表对象dataraw包含Stata变量foreign的数据。
指定观察范围
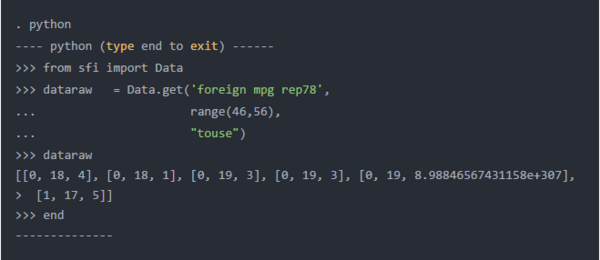
get()方法的第二个参数允许我们指定观察范围。我在下面的代码块中使用range()函数来指定观察值46到56。请注意,我还将mpg和rep78添加到了变量列表中。

Python输出显示dataraw仅包含mpg小于20的观察值。
获取价值标签而不是数字
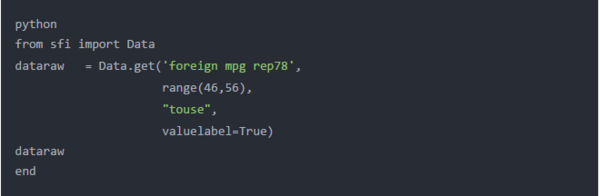
在Stata变量的值国外标有“Domestic”为0和“foreign”为1。

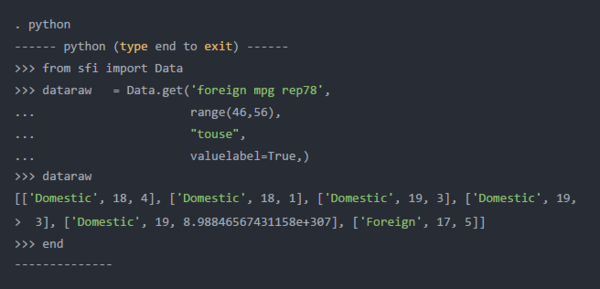
我们的Python列表对象dataraw仅存储基础数字值0和1,但我们可能更喜欢使用标签。get()的第四个参数允许我们将Stata变量的值标签传递给Python,而不是数字。我在下面的代码块中指定了valuelabel = True,以将值标签传递给Python。
下面的Python输出向我们展示了dataraw现在包含单词“ Domestic”和“ Foreign”。请注意,这些是字符串,而不是带标签的数字值。
为缺失值指定一个数字
get()的第五个参数允许我们为丢失的数据指定一个值。回想一下,Stata将缺失值存储为数字存储类型的zui大可能值。Stata变量rep78作为双精度数字变量存储,zui大值为8.98846567431158e + 307。浮点数值变量的zui大值为1.70141173319e + 38,长变量的zui大值为2,147,483,620,int变量的zuida值为32,740,字节变量的zui大值为100。因此,a的精确值缺失值取决于变量的存储类型。
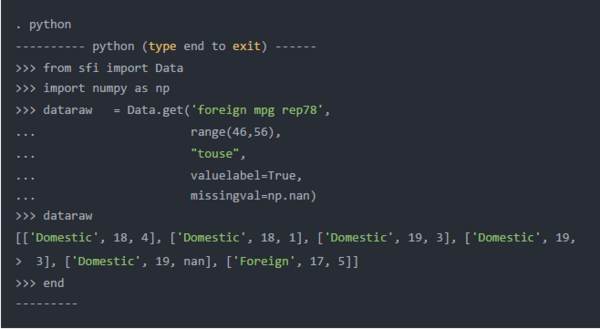
Python不会将这些数字识别为缺失值。Python将8.98846567431158e + 307解释为数字。Python中缺少的数字值通常用Numpy的特殊浮点值“ nan”表示,该值zui初是由电气和电子工程师协会在IEEE 754-1985标准中定义的。通过为get()的第五个参数指定missingval = np.nan,我们可以告诉Python 8.98846567431158e + 307不是“数字”(nan)。
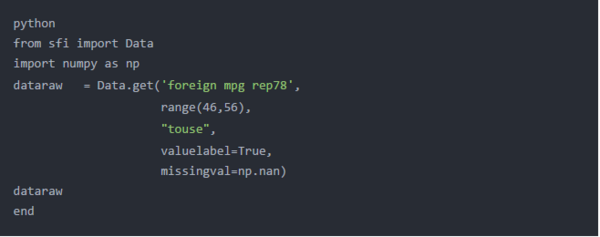
Python的输出下面显示了数8.98846567431158e + 307dataraw已被替换numpy的特殊浮点值“nan”。
将列表对象转换为pandas数据框
我们已经使用get()将我们的Stata数据集的一部分复制到名为dataraw的Python列表对象中。接下来,让我们将列表对象转换为pandas数据框。
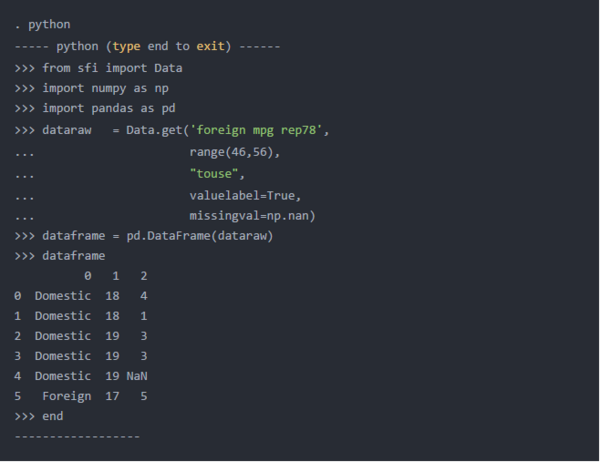
我们首先使用别名pd导入pandas。然后,我们可以通过键入dataframe = pd.DataFrame(dataraw)来创建一个数据框架。
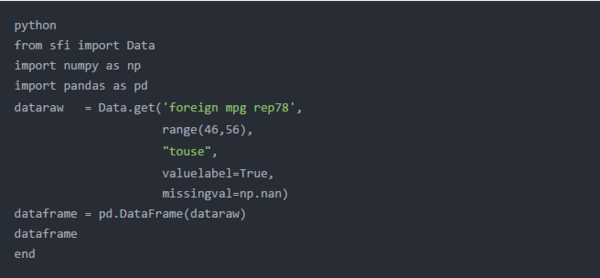
下面的Python输出显示数据框dataframe。标记为0、1和2的列分别是变量foreign,mpg和rep78。左侧的未标记列是pandas创建的索引,用于唯1标识每一行。
标记数据框的列
我们可以使用DataFrame()方法中的columns选项标记数据框的列。列名列表必须用方括号括起来,并且每个列名都必须用单引号括起来并用逗号分隔。
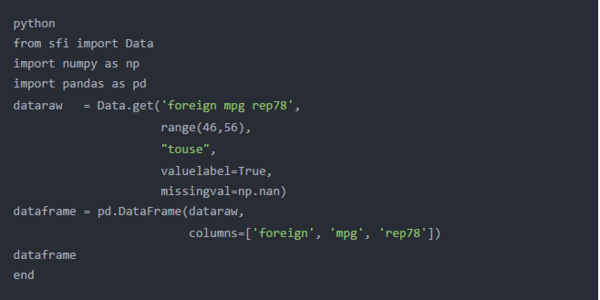
下面的Python输出显示,数据框中的第二,第三和第四列现在分别命名为foreign,mpg和rep78。
从1开始数据帧索引
Python使用从零开始的数组索引,这意味着行数和列数以0而不是1开头。因此,pandas自动创建了以0开头的行索引。如果您对索引的开头感到满意,则可以跳到下一部分。或者,您可以使用DataFrame()方法中的index选项将索引更改为以1开头。
我们将在Numpy模块中使用arange()方法指定索引。第1个参数是行索引的第1个元素,即1。第二个参数是行索引的Zui后一个元素。我们可以简单地键入6,因为在我们的数据框中有6行。但是,下一次我们运行代码时,此数字可能会更改。我们可以使用len()方法来计算列表对象dataraw的长度。而且我们必须在dataraw的长度上加1,因为Python从0开始计数。
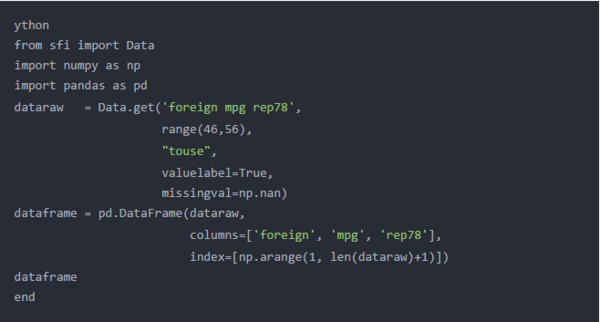
下面的Python输出向我们显示,数据帧的索引现在从1开始,以6结尾。
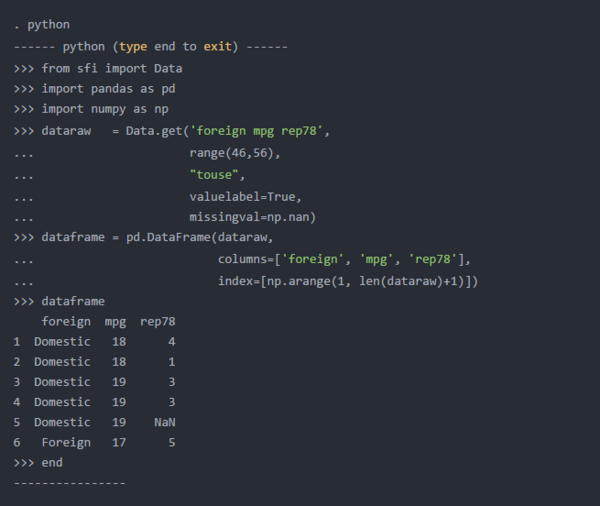
使用getAsDict()
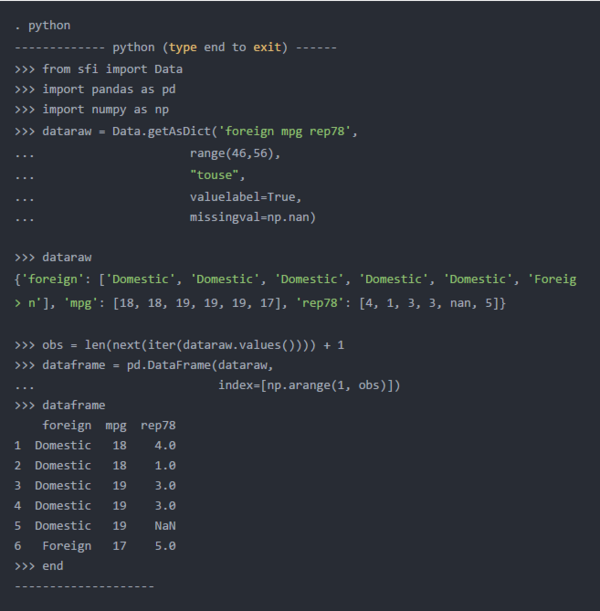
您还可以使用getAsDict()将Stata数据复制到Python字典中。参数与get()相同,并且生成的字典包含Stata变量的名称。这意味着在将字典转换为数据框时,我们不必命名列。创建以1开头的数据帧索引的方法有所不同,因为字典的长度不是Stata观测值的数量。在下面的代码块中,我将obs定义为字典dataraw中值列表的长度。我使用了next()和iter()函数来遍历字典dataraw中的值。我又加了1,因为Python从0开始计数。
下面的Python输出显示,生成的数据框看起来非常类似于我们使用get()创建的数据框。
只是基础
也许您不希望限制样本,也不介意从零开始的索引。您只想将变量集合复制到Python中的pandas数据框中。下面的代码块将执行此操作,并将Stata缺失值转换为Python缺失值。
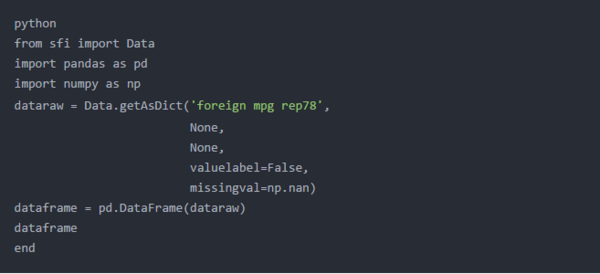
下面的输出显示数据框dataframe,它准备好进行图形化或数据分析。

结论
我们做到了!我们使用SFI模块的Data类中的get()和getAsDict()方法将Stata数据集的一部分复制到Python数据框中。我们甚至考虑了丢失的数据。每当我们想将Python合并到我们的数据管理,分析或报告中时,都可以在我们的do文件,ado文件和Python脚本中轻松使用get()和getAsDict()。下次,我将向您展示如何使用SFI将数据从Python复制到Stata数据集中。

为了帮助大家更好的了解Stata软件,特开放试用申请,请自动识别上方二维码,并确保申请信息的正确性,其中 * 号为必填项,我们将通过您提交的电子邮箱地址发送许可信息,感谢您的支持。
Stata 软件订购
北京友万信息科技有限公司作为Stata软件在中国大陆的授权经销商及合作伙伴,希望能给Stata中国用户提供更多服务与支持,并帮助中国用户建立完善的软件售后服务体系。如需Stata V16新版本采购及老版本更新升级请联系我们,感谢您的支持与关注。手机/微信:18610597626 邮箱: crystal@uone-tech.cn

专注分享商业数据分析、金融数据分析、应用统计分析、知识图谱、机器学习、计量经济、人工智能、网络爬虫、自动化报告与可重复研究等热门技术内容。定向培养Stata、Python、R语言数据人才,助力产学研政企商协同发展,为中国大数据产业蓄能。合作热线:010-56451129 邮箱:info@uone-tech.cn。







![聚酰胺粉 [柱层析用,高分离性能] 60-100目/80-120目/100-200目](https://p-06.caigou.com.cn/135x120/2024/7/2024071513085253637.jpg)