GraphPad Prism 9.0正式发布
GraphPad Prism 9已正式发布!Prism 9对多变量数据表进行了许多重大改进。 如增加的数据限制、自动识别变量类型、自动变量编码等,使用标准结构探索更大的数据集,分析和处理更高维度的数据!


更高维度的数据!
Prism 9对多变量数据表进行了许多重大改进。使用标准结构探索更大的数据集,并通过以下改进执行新的和改进的分析:
增加的数据限制-在每个数据表中zui多输入1024列数据
自动识别变量类型-将多变量数据表中的变量识别为连续值,分类值或标签值
数据表中的文本信息-直接以文本形式输入数据。无需编码“ 0”和“ 1”之类的变量,只需直接在数据表中输入“ Male”和“ Female” 自动变量编码-输入您的数据,让Prism负责其余的工作。Prism会自动将分类文本变量编码为数字“虚拟”变量 通常,在研究中,我们发现自己拥有大量有关实验中不同变量的信息。举一个简单的例子,想象一下在给个体服用旨在降低血压的实验药物或安慰剂后测量他们的血压。除了记录的血压测量值外,您还可能记录了有关每个受试者的年龄,身高,体重,性别,种族以及许多其他潜在变量的大量信息。
设计了许多统计技术来分析这类“多变量”数据,例如多元线性回归和多元逻辑回归。使用这些类型的“多个变量”分析意味着您可以探索感兴趣的结果而不会浪费任何可能有用的信息。为了促进这种增加的数据信息密度,Prism提供了我们的多变量数据表以将数据容纳在标准数据结构中,该数据结构几乎被其他统计软件普遍使用并打包在那里(例如R,SPSS和MATLAB)。在这种格式下,每一列代表一个不同的变量,而每一行代表一个不同的主题(每个主题的每个变量的测量值将放入该主题所在行的相应列中)。
主成分分析(PCA)
有时,收集的变量数量远远超过可供研究的学科数量。考虑基因表达研究,其中从分为两组的受试者中测量了成百上千种不同基因的表达水平:治疗组和对照组。可能仅仅是变量太多而无法使模型适合数据。但是,选择一些要从分析中排除的变量只会丢掉可能有用的信息!PCA是一种“降维”技术,可用于减少所需变量的数量,同时从数据中消除尽可能少的信息。
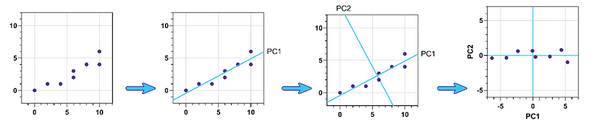
PCA中可用的其他功能包括:
通过平行分析(以及Kaiser方法,总方差阈值方法等)选择组件
碎石图,分数图和双线图的生成
自动准备PCA结果以进一步用于多元线性回归(主成分回归)
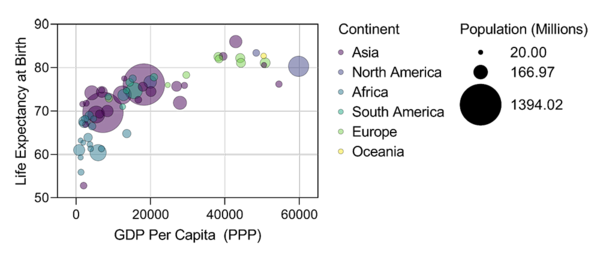
向图形添加新尺寸
直接从原始数据,符号位置(X和Y坐标),大小和填充颜色的编码变量创建气泡图。请注意,可以使用分类(分组)或连续变量来定义符号颜色和符号大小。
-更多资源请访问【友万科技】官网,以便获取更多软件信息,感谢您的支持与理解。











![聚酰胺粉 [柱层析用,高分离性能] 60-100目/80-120目/100-200目](https://p-06.caigou.com.cn/135x120/2024/7/2024071513085253637.jpg)